
Bi-Directional Database Synchronization
Posted
on
in
Database
• 1092 words
• 6 minute read
Tags:
Database
Recently, I had an opportunity to work with real-time user’s data synchronization across two databases, where any change in one database must be reflected in the other. The challenge was to implement bi-directional synchronization with low latency and cost efficiency.
In our setup, one database was hosted on-premises, while the other is on Azure. We initially explored Azure Data Factory pipelines and other cloud-native solutions. While these options were feasible, but we aimed for something that is light weight, easy to setup and maintain.
That’s where we came across SymmetricDS a powerful open-source tool for data replication and synchronization.
Introduction to SymmetricDS
SymmetricDS is an open source tool, that helps to keep data in sync between two or more databases. It supports heterogeneous databases and bi-directional data synchronization.
In simple, it uses triggers to detect the changes and shares them over network.
SymmetricDS Version: 3.16.4
Our Use Case
In our case, we needed to achieve bi-directional synchronization between two SQL Server databases (one on-prem and one in Azure). SymmetricDS was a good solution because,
- Change Data Capture (CDC), Detect’s changes in real-time.
- Cross-database replication with minimal configuration.
- In-Built Retry Mechanism
SymmetricDS Architecture – How It Works
SymmetricDS is built using Java and uses database trigger based replication mechanism. For each database in the synchronization network, SymmetricDS runs an engine responsible for tracking data changes and sending them to other nodes,.
Key Architectural Components
1. Nodes
- Each database participating in this sync process is referred to as a node.
- Nodes can be root (main) where the registration takes place or child (client) nodes.
- Each node runs its own SymmetricDS engine, maintaining metadata about other nodes.
2. Engine
The engine is a Java process that:
- Monitors changes via database triggers.
- Batches data into outgoing queues.
- Uses HTTP(S) for data transmission.
- Handles conflict resolution and error recovery.
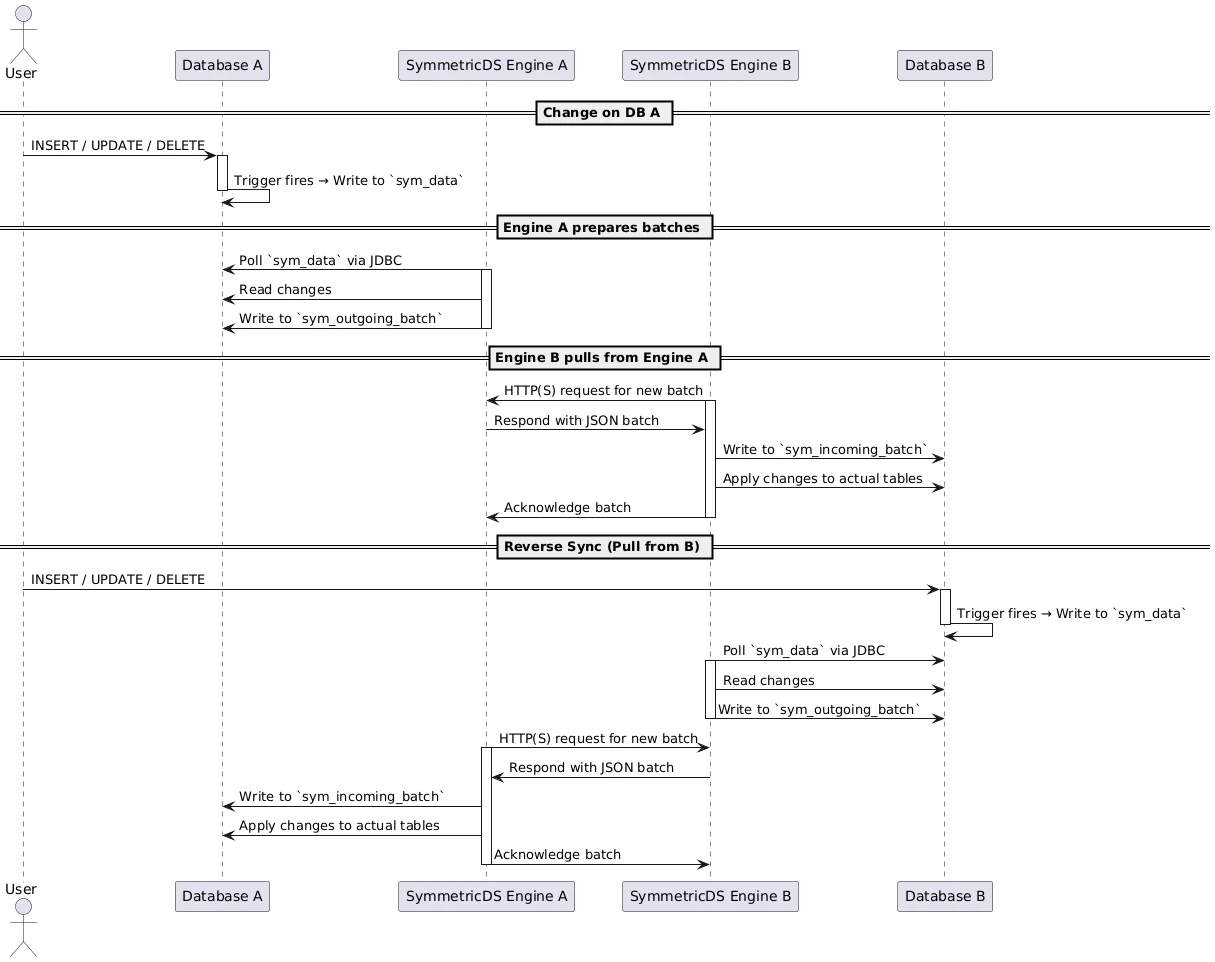
The engines run independently on the SymmetricDS server and the databases runs elsewhere. So how do they connect, communicate and synchronize ?
During initialization, SymmetricDS creates special sym_* tables and database triggers. Whenever an INSERT, UPDATE or DELETE happens on a table, the corresponding trigger writes a changes into the sym_data table.
The engine continuously polls the sym_data table using direct JDBC connectivity to detect changes.
The engine then groups these changes into batches, which are stored in the sym_outgoing_batch table. Then they are transmitted to other nodes over network.
User modifies DB table (INSERT/UPDATE/DELETE)
↓
Database Trigger fires (on that table)
↓
Trigger writes change info to `sym_data`
↓
SymmetricDS engine polls `sym_data`
↓
Engine batches changes → sym_outgoing_batch
↓
Transmits as JSON → HTTP(S) → Remote Node
Flow Diagram
Internal Tables
SymmetricDS maintains internal tables, such as:
sym_node– Stores node details.sym_trigger– Tracks which tables/columns are monitored.sym_router– Routes data changes between nodes.sym_data– Logs detected changes.sym_outgoing_batch&sym_incoming_batch– Tracks data batches.
Step-by-Step Setup
Step 1 - Download SymmetricDs
Download & Extract SymmetricDs ZIP.
Folder Structure
symmetric-server-<version>/
├── bin/ # Startup and shutdown scripts (e.g., sym, sym.bat, sym.sh)
├── conf/ # Global configuration files (e.g., log4j2.xml, security.properties)
├── engines/ # Engine instance folders (each node’s properties file lives here)
│ ├── <engine-name>.properties
│ ├── ...
├── lib/ # All required Java libraries and drivers (JAR files)
├── logs/ # Log files generated at runtime (by default, symmetric.log)
├── sql/ # SQL scripts for creating/upgrading SymmetricDS database tables
├── samples/ # Example engine.properties files, configurations, or samples
├── tmp/ # Temporary files (runtime)
├── web/ # Web-related files for embedded web server
├── triggers/ # Custom triggers/scripts if you use them
└── README.txt # Documentation
Step 2 – Properties File
Navigate to /engines and create cloud.properties and onprem.properties files.
Warning
Attention: While configuring SymmetricDS, ensure that the identifiers are set correctly and uniquely based on your environment.
Incorrect configuration can lead to:
- Sync failures or data not syncing
- Conflicts between nodes
- Misrouted or duplicate data
Always verify these values before proceeding with setup or applying any sample queries. In example queries please check node_id, node_group_id, router_id, external_id before you execute
Example: Main Node
# === Basic engine info ===
engine.name=main-node
external.id=main-node
group.id=mssql
# === Sync URL ===
# sync.url=http://<symmetrics-ip>:31415/sync/main-node
sync.url=https://symmetrics.domain.local/sync/main-node
# === Registration ===
registration.server.enabled=true
auto.registration=true
# Since this is main node. Registration URL should be empty.
registration.url=
# === Database ===
db.driver=com.microsoft.sqlserver.jdbc.SQLServerDriver
# db.url=jdbc:sqlserver://<Node-ip>:1433;databaseName=<DBName>;encrypt=false
db.url=jdbc:sqlserver://<MainNodeURL>;databaseName=<DBName>;encrypt=false
db.user=sa
db.password=YourStrong!Passw0rd
# === Properties Related to Sync Time ===
job.routing.period.time.ms=5000
job.push.period.time.ms=5000
job.pull.period.time.ms=5000
Example: Client Node
# Node 2 Properties
# === Basic engine info ===
engine.name=node2
external.id=node2
group.id=mssql
# === Sync URL ===
# sync.url=http://<symmetrics-ip>:31415/sync/node2
sync.url=https://symmetrics.domain.local/sync/node2
# === Registration ===
# registration.url=http://<symmetrics-ip>:31415/sync/main-node
registration.url=https://symmetrics.domain.local/sync/main-node
# === Database ===
db.driver=com.microsoft.sqlserver.jdbc.SQLServerDriver
# db.url=jdbc:sqlserver://<Node-ip>:1433;databaseName=<DBName>;encrypt=false
db.url=jdbc:sqlserver://<Node2URL>;databaseName=<DBName>;encrypt=false
db.user=sa
db.password=YourStrong!Passw0rd
# === Properties Related to Sync Time ===
job.routing.period.time.ms=5000
job.push.period.time.ms=5000
job.pull.period.time.ms=5000
Step 3 – Enable Debug Logging
Edit conf/log4j2.xml and add:
<Logger name="org.jumpmind.symmetric" level="DEBUG" />
Step 4 – Start SymmetricDS
By default the nodes pull the changes. If needed we can change this behaviour to PUSH. So once a change happens in a node the change is immediately pushed to other nodes.
(Please check the sym_node_group_link table before updating)
data_event_action = 'P'(Push): The source node group sends its data changes to the target node group.data_event_action = 'W'(Pull): The source node group waits for the target node group to request data changes, effectively acting as a pull mechanism.
UPDATE sym_node_group_link
SET data_event_action = 'P'
WHERE source_node_group_id = 'mssql' AND target_node_group_id = 'mssql';
Start the server:
./sym
Step 5 – Create Triggers
Create a sample table and link it with a trigger:
-- Create table in both the nodes (to reduce complexity)
CREATE TABLE employee (
id INT PRIMARY KEY,
name NVARCHAR(100),
department NVARCHAR(50)
);
-- Run in the Main Node/DB alone it should sync with other DB too
INSERT INTO sym_trigger (trigger_id, source_table_name, channel_id, sync_on_insert, sync_on_update, sync_on_delete)
VALUES ('employee_trigger', 'employee', 'default', 1, 1, 1);
INSERT INTO sym_trigger_router (trigger_id, router_id)
VALUES ('employee_trigger', 'mssql to mssql');
Now try Insert / Update / Delete with the data it should be automatically synced across nodes
-- Insert on Node 1:
INSERT INTO employee (id, name, department) VALUES (9001, 'Alice Cloud', 'Finance');
-- Insert on Node 2:
INSERT INTO employee (id, name, department) VALUES (9002, 'Bob OnPrem', 'IT');
-- Update from Node 1:
UPDATE employee SET department = 'Executive IT' WHERE id = 9001;
-- Delete from Node 2:
DELETE FROM employee WHERE id = 9002;
Conclusion
SymmetricDS helped us to keep data in sync between our on-prem and cloud databases without need for complex setup or custom solutions. It uses database triggers to detect changes, handles conflicts and works in a decentralized way.